
The jig: What makes Irish traditional music feel right?
Table of Contents
I’m learning to play Anglo concertina. The instrument is beautiful, the tunes are addictive, and I sound like a dying bird being attacked by a cat especially in the upper registers.
One thing I’ve been obsessing over (and my teachers are really pushing me on): why do some players make jigs bounce while others (me) make them plod? So naturally, I did what any reasonable person would do: analyze recordings of master players using a Python lib i wanted to play with.
Background
Irish jigs are in 3, more accurately 6/8 time — two groups of three eighth notes per bar. The first note of each group (the “downbeat”) supposedly gets emphasis. But what kind of emphasis? Louder? Longer? Both? And how much?
The tool: librosa
Librosa is a Python library for audio analysis. It can detect note onsets, estimate tempo, extract amplitude envelopes, and much more. Here is where i started:
pip install librosa scipy numpy matplotlib
The key functions I used:
librosa.onset.onset_detect()— finds when notes startlibrosa.beat.beat_track()— identifies the beat structurelibrosa.feature.rms()— measures loudness over time
Dead ends and wrong turns
Before finding the right approach, I tried several visualization methods that were interesting. Note that these were done on different tunes; I’m showing you to give a sense of what kinds of visualisations you could explore.
Consecutive note duration ratios
I looked at the ratio between each note’s duration and the next note’s duration. The histogram showed a bimodal distribution — lots of ratios around 0.5 and around 2.0.
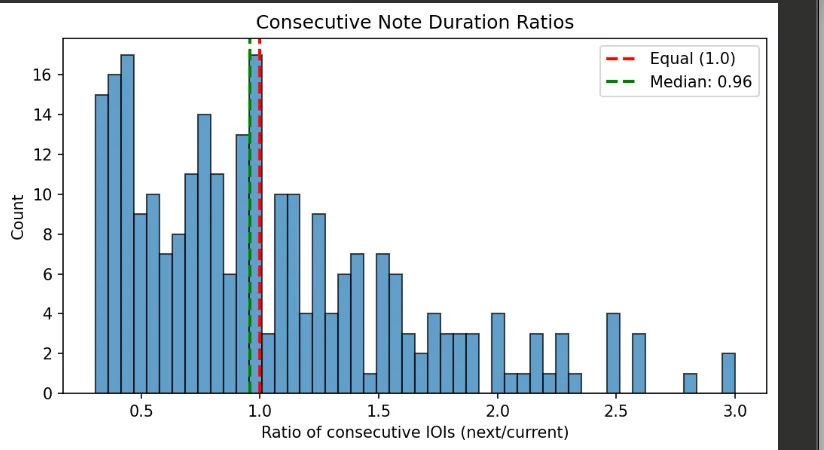
The peak below 1.0 means many notes are followed by longer notes. The peak above 1.0 means many notes are followed by shorter notes.
Duration vs amplitude scatter
I plotted each note pair’s duration ratio against its amplitude ratio. The four quadrants show different combinations: first note longer/shorter, first note louder/quieter.
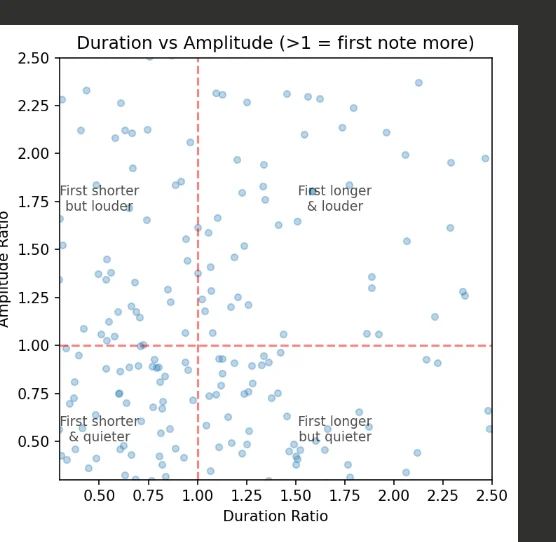
Most points cluster in the “first longer & louder” quadrant (upper right).
Swing ratio over time
I tracked how the duration ratio changed throughout a tune. The rolling average shows it fluctuates significantly. the player isn’t robotic.
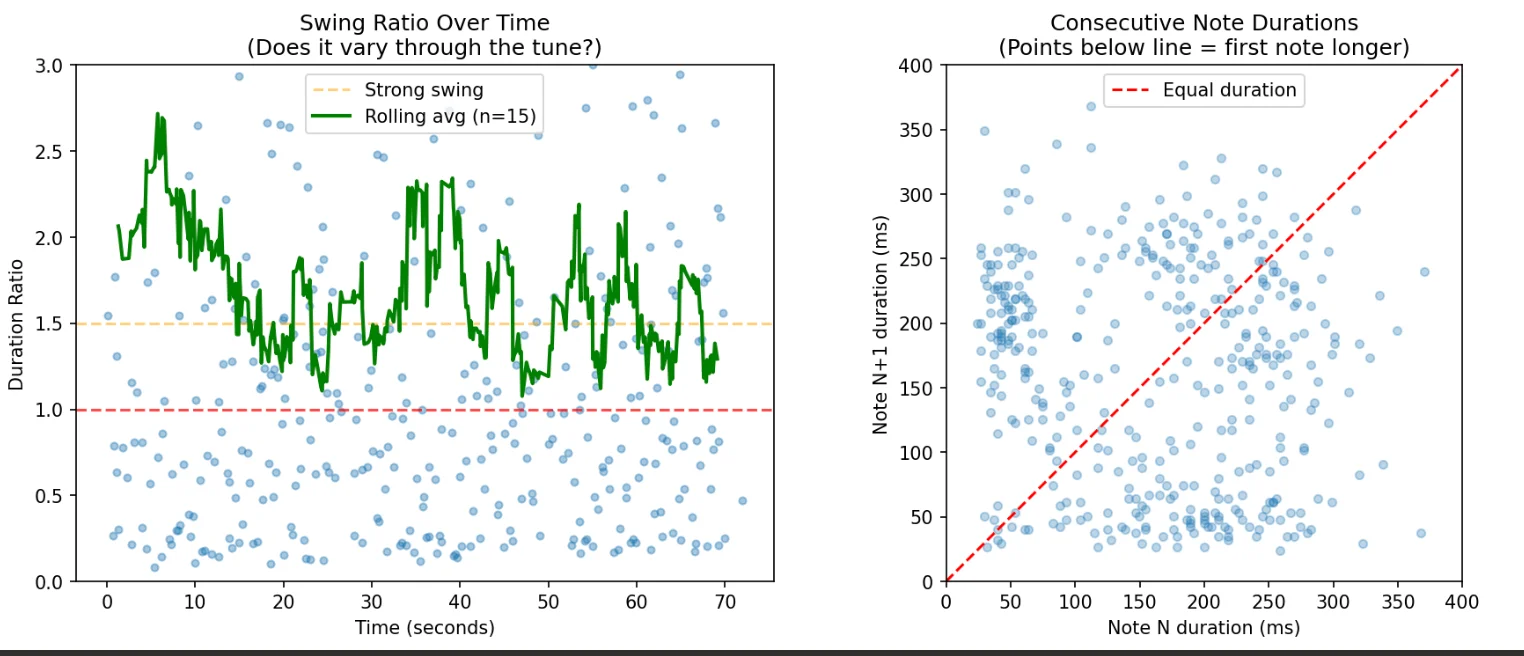
Align with detected beats
I used librosa’s beat detection to identify actual downbeats, then compared downbeats directly against off-beats.
# Get beats (downbeats)
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
# Get all note onsets
onset_frames = librosa.onset.onset_detect(y=y, sr=sr, hop_length=128, backtrack=True)
onset_times = librosa.frames_to_time(onset_frames, sr=sr, hop_length=128)
# Classify each onset as downbeat or off-beat
tolerance = 0.05 # 50ms window
is_downbeat = np.zeros(len(onset_times), dtype=bool)
for bt in beat_times:
distances = np.abs(onset_times - bt)
closest = np.argmin(distances)
if distances[closest] < tolerance:
is_downbeat[closest] = True
Now I could directly compare:
- Amplitude: Are downbeats louder?
- Duration: Are downbeats held longer?
Results: 17 jigs from 5 players
I analyzed recordings from several concertina players:
| Artist | Tunes | Avg Amplitude | Avg Duration |
|---|---|---|---|
| Mary MacNamara | 5 | +35% | +29% |
| Brenda Castles | 2 | +17% | +42% |
| Dympna O’Sullivan | 4 | +14% | +44% |
| Glackin & Flynn | 4 | +1% | +46% |
| Hugh Healy | 2 | +2% | +33% |
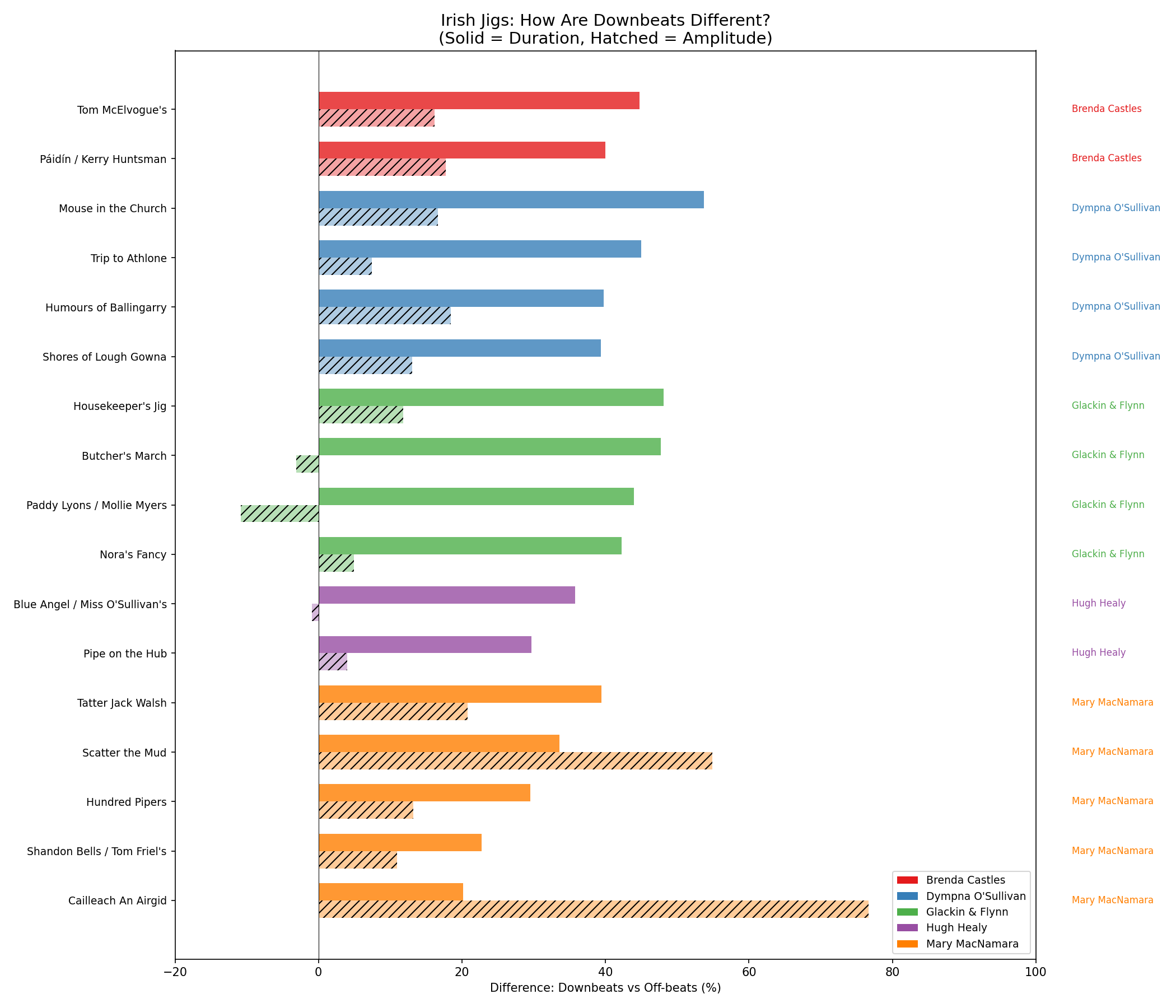
What I learned
Duration always. Every single tune across all players showed downbeats held 20-46% longer than off-beats. This is the foundation of the “lift.”
Amplitude varies dramatically by player style. Mary MacNamara punches downbeats hard (+35% louder on average, up to +77% on some tunes). You can kind of see that in how she bounces both feet as she plays. Glackin & Flynn barely use dynamic accent at all (+1%) but have the strongest duration contrast. Both sound great - they’re just different approaches.
The code
Here’s the core analysis function. Feed it any audio file and it returns the percentage difference in amplitude and duration between downbeats and off-beats:
#!/usr/bin/env python3
"""
Analyze downbeat vs off-beat characteristics in Irish traditional music.
Usage:
from analyze_jig import analyze_file
result = analyze_file("/path/to/file.mp3")
print(f"Amplitude: {result['amp_diff']:+.1f}%")
print(f"Duration: {result['dur_diff']:+.1f}%")
"""
import librosa
import numpy as np
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
def analyze_file(filepath):
"""
Analyze a single audio file for downbeat characteristics.
Returns dict with:
- amp_diff: % difference in amplitude (downbeats vs off-beats)
- dur_diff: % difference in duration (downbeats vs off-beats)
- amp_p: p-value for amplitude difference
- dur_p: p-value for duration difference
- tempo: detected tempo in BPM
- n_downbeats: number of downbeats detected
- n_offbeats: number of off-beats detected
"""
y, sr = librosa.load(filepath, sr=None)
# Get beats (downbeats)
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
if hasattr(tempo, '__len__'):
tempo = float(tempo[0])
# Get all note onsets
onset_frames = librosa.onset.onset_detect(
y=y, sr=sr, hop_length=128, backtrack=True
)
onset_times = librosa.frames_to_time(
onset_frames, sr=sr, hop_length=128
)
# Get RMS amplitude at each onset
rms = librosa.feature.rms(y=y, hop_length=128)[0]
rms_times = librosa.frames_to_time(
np.arange(len(rms)), sr=sr, hop_length=128
)
onset_amps = []
for ot in onset_times:
idx = np.argmin(np.abs(rms_times - ot))
onset_amps.append(rms[idx])
onset_amps = np.array(onset_amps)
# Inter-onset intervals (note durations)
ioi = np.diff(onset_times) * 1000 # milliseconds
# Classify each onset as downbeat or off-beat
tolerance = 0.05 # 50ms
is_downbeat = np.zeros(len(onset_times), dtype=bool)
for bt in beat_times:
distances = np.abs(onset_times - bt)
closest = np.argmin(distances)
if distances[closest] < tolerance:
is_downbeat[closest] = True
# Compare amplitudes
downbeat_amps = onset_amps[is_downbeat]
offbeat_amps = onset_amps[~is_downbeat]
amp_diff = 100 * (np.mean(downbeat_amps) / np.mean(offbeat_amps) - 1)
# Compare durations
downbeat_indices = np.where(is_downbeat)[0]
offbeat_indices = np.where(~is_downbeat)[0]
downbeat_ioi = [ioi[i] for i in downbeat_indices if i < len(ioi)]
offbeat_ioi = [ioi[i] for i in offbeat_indices if i < len(ioi)]
# Filter out phrase breaks
median_ioi = np.median(ioi)
downbeat_ioi = [x for x in downbeat_ioi if x < median_ioi * 2.5]
offbeat_ioi = [x for x in offbeat_ioi if x < median_ioi * 2.5]
dur_diff = 100 * (np.mean(downbeat_ioi) / np.mean(offbeat_ioi) - 1)
# Statistical significance
_, p_amp = stats.ttest_ind(downbeat_amps, offbeat_amps)
_, p_dur = stats.ttest_ind(downbeat_ioi, offbeat_ioi)
return {
'amp_diff': amp_diff,
'dur_diff': dur_diff,
'amp_p': p_amp,
'dur_p': p_dur,
'tempo': tempo,
'n_downbeats': int(np.sum(is_downbeat)),
'n_offbeats': int(np.sum(~is_downbeat)),
}
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("Usage: python analyze_jig.py <audio_file>")
sys.exit(1)
result = analyze_file(sys.argv[1])
amp_sig = "*" if result['amp_p'] < 0.05 else ""
dur_sig = "*" if result['dur_p'] < 0.05 else ""
print(f"Tempo: {result['tempo']:.0f} BPM")
print(f"Downbeats: {result['n_downbeats']}, Off-beats: {result['n_offbeats']}")
print(f"Amplitude: {result['amp_diff']:+.1f}%{amp_sig}")
print(f"Duration: {result['dur_diff']:+.1f}%{dur_sig}")
print(f"\n* = statistically significant (p < 0.05)")
Run it on any jig recording:
python analyze_jig.py "some_tune.mp3"
# Output:
# Tempo: 120 BPM
# Downbeats: 180, Off-beats: 540
# Amplitude: +15.2%*
# Duration: +42.3%*
Next steps
What’s wild is even though I’ve known this for a while, and I can hear it in recordings - I need to actually train my fingers to do it. That’s a different kind of problem - one that Python can’t solve for me. But it’s a pretty fun one!
The recordings analyzed are from albums I purchased and highly recommend:
- The Light Side of the Tune — Brenda Castles <== this is my favorite Concertina album
- Traditional Music from East Clare — Mary MacNamara
- The Housekeepers — Doireann Glackin & Sarah Flynn
- Enriched. Saibhriú — Dympna O’Sullivan
- Ceolaire — Hugh Healy



